crawler
0. 前言
爬虫其实就像是一个自动化的网络助手,它能够像人一样浏览网页,但是速度更快,效率更高。简单来说,爬虫就是一个程序,它可以自动访问网页,读取网页上的内容,并把你想要的信息提取出来。
举个例子:想象一下,你想了解某个商品的价格,通常你会打开网站,搜索这个商品,然后手动记录下它的价格。爬虫可以帮你做这件事,程序会自动打开网页,搜索商品,并把价格信息提取出来,甚至可以保存到一个文件里,这样你就不用自己一个一个去查找了。
爬虫可以用于很多场景,比如从多个网站上收集商品信息,追踪新闻动态,甚至是抓取社交媒体上的数据。总之,爬虫就是一个帮你自动从互联网上获取数据的工具。
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP,JAVA,C#,C++,Python,选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
本文使用的语言为python,IDE为pycharm
1. 框架
本文使用的是Requests + Beautifulsoup组合作为框架,这也是一个非常经典的组合
他的原理是这样的:
- Requests发送HTTP请求,比如获取网页的HTML内容
- Beautifulsoup用于解析HTML并从中提取所需的数据
2. 基础知识介绍
2.1 Requests
什么是requests库
requests 库主要用于与 Web
服务进行通信。发送请求后服务器返回的响应会包含很多信息。requests库可以处理响应和管理对话
**如何使用
首先,我们要安装Requests库
1 | |
下面案例是Requests库中get()方法发送一个get请求
1 | |
运行效果
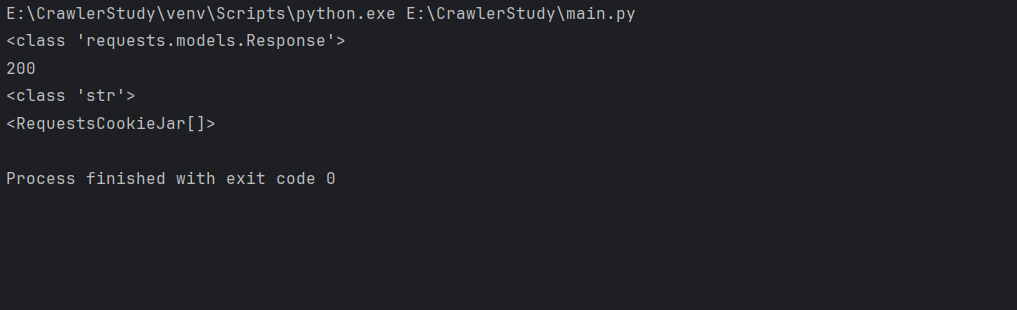
查看响应的内容
1 | |
小贴士
常见的状态码包括:
200 OK:请求成功,服务器返回了所请求的资源404 Not Found:服务器找不到请求的资源500 INternal Server Error:服务器内部错误常见方法内容类型包括:
text/html:表示内容是HTML文档application/json:表示内容是JSON数据image/png:表示内容是啥PNG图片
- 用途:
- 如果是HTML,你可以用
BeautifulSoup解析- 如果是JSON,你可以用python的
json模块解析- 如果是图片或文件,你可以保存他们
Cookies
- Cookies 是由服务器生成并发送到客户端(通常是浏览器)的小数据片段,这些数据会被浏览器存储并在随后的请求中发送回服务器。Cookies 通常用于以下目的:
- 会话管理:比如登陆状态、购物车内容等
- 个性化设置:比如用户的语言偏好、主题颜色等
- 用户跟踪:比如统计用户的访问行为,广告投放等
<RequestsCookieJar[]>时,这表示当前RequestsCookieJar对象是空的,即没有任何 Cookies 存储在其中。
其他类型的请求:
1 | |
2.2 BeautifulSoup库
什么是BeautifulSoup库?
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python
库。它可以把复杂的 HTML 文档转换成一个复杂的树形结构,其中每个节点都是
Python 对象,表示 HTML 文档中的一部分,比如标签、属性、文本等。
BeautifulSoup
使得从网页中提取数据变得非常简单。你可以通过标签名、属性、CSS
选择器等方式来查找和操作网页内容。
原理:实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中。之后通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
使用BeautifulSoup库
首先,我们要安装BeautifulSoup
1 | |
接着,导入从bs4包中导入BeautifulSoup类
1 | |
要使用BeautifulSoup解析HTML文档,我们要先获取HTML文本
1 | |
下面是一些常见操作:
查找元素
- 按标签名查找单个元素
find():返回第一个匹配的元素1
2
3title_tag = soup.find('title')
print(title_tag) # 输出<title>Dumpling</title>
print(title_tag.string) # 输出Dumpling- 按标签名查找所有元素
find_all():返回所有匹配的元素,返回一个列表1
2
3
4
5all_headers = soup.find_all('h2', class_="index-header")
for header in all_headers:
content = header.find('a')
print(f"{content.text.strip()}")- 按标签名和属性查找元素
1