python学习
1. python基础教程
1.1 python关键字和标识符
1.1.1 python关键字
关键字是Python中的保留字。
我们不能将关键字用作变量名,函数名或任何其他标识符。它们用于定义Python语言的语法和结构。
在Python中,关键字区分大小写。
Python 3.7中有 33 个关键字。该数字在一段时间内可能会略有变化。
所有关键字必须是小写的,其中 True,False 和 None 除外。下面列出了所有关键字。
python中的关键字
| False | await | else | import | pass |
|---|---|---|---|---|
| None | break | except | in | raise |
| True | class | finally | is | return |
| and | continue | for | lambda | try |
| as | def | from | nonlocal | while |
| assert | del | global | not | with |
| async | elif | if | or | yield |
1.1.2 python标识符
标识符是给诸如类,函数,变量等实体的名称。它有助于将一个实体与另一个实体区分开。
编写标识符的规则:
- 标识符可以是小写字母(a 至 z)或大写字母(A 至 Z)或数字(0 至 9)或下划线(_)的组合。myClass,var_1,var_name_1, print_this_to_screen 都是有效的。
- 标识符不能以数字开头。1variable 是无效的,但 variable1 是有效的。
- 关键字不能用作标识符。
- 我们不能使用像!。,**@**,#,$,%等这样的特殊符号。
- 标识符可以是任意长度
注意:
Python 是 区分大小写 的语言。这意味着 Variable 和 variable 是两个不同的变量。同时,也建议大家,在实际编程中,始终命名有意义的标识符。
虽然,c = 10 也是有效的。但是使用 count = 10 看起来会更有意义,并且即使您在经过一段长时间的间隔之后查看代码,也更容易弄清楚它的作用和它所代表的意义。
1.2 python语句,缩进和注释
1.2.1 python语句
Python解释器可以执行的指令称为语句。例如,a = 1 是一个赋值语句。if 语句,for 语句,while 语句等是其他种类的语句,将在后面讨论。
多行语句
在Python中,语句的结尾用换行符标记。但是我们可以使一条语句扩展到具有多行连续字符()的多行。例如:
1 | |
这是显式的行继续。在Python中,在圆括号(),方括号[]和花括号{}中暗含换行符。例如,我们可以将上述多行语句实现为:
1 | |
在此。周围的括号()隐式地进行了行连续。[]和{}也是如此。例如:
1 | |
我们还可以使用分号将多个语句放在一行中,如下所示
1 | |
1.2.2 python缩进
大多数编程语言(例如C,C ++,Java)都使用大括号{}来定义代码块。而Python使用缩进。
代码块(函数的主体,循环的主体等)以缩进开始,以第一条未缩进的行结束。缩进量取决于您,但是在整个块中缩进量必须保持一致。
通常,四个空格用于缩进,并且优先于制表符。下面是一个示例。
Python中缩进的实现使代码看起来整洁干净。这导致看起来相似且一致的Python程序。
缩进可以在连续行中忽略。始终缩进是个好习惯。它使代码更具可读性。例如:
1 | |
和
1 | |
两者都是有效的并且做同样的事情。但是前一种风格更加清晰。
缩进不正确将导致IndentationError。
1.2.3 python注释
编写程序时,注释非常重要。它描述了程序内部正在发生的事情,这样,查看源代码的人就不会很费解。您可能会忘记一个月前刚编写的程序的关键细节。因此,花时间以注释的形式解释这些概念总是很有意义的。
在Python中,我们使用井号(#)开始编写注释。
它扩展到换行符。注释供程序员使用,以更好地理解程序。Python解释器忽略注释。
1 | |
多行注释
如果我们有扩展多行的注释,一种方法是在每行的开头使用哈希(#)。例如:
1 | |
这样做的另一种方法是使用三引号,''' 或者 """。
这些三引号通常用于多行字符串。但是它们也可以用作多行注释。除非它们不是文档字符串,否则它们不会生成任何额外的代码。
1 | |
python中的文档字符串
Python中的文档字符串
Docstring是文档字符串的缩写。
它是一个字符串,作为模块,函数,类或方法定义中的第一条语句出现。我们必须在文档字符串中写出函数/类的作用。
编写文档字符串时使用三引号。例如:
1 | |
Docstring作为__doc__函数的属性可供我们使用。运行上面的程序后,在shell中发出以下代码。
1 | |
输出
1 | |
1.3 python变量,常量和字面量
1.3.1 python变量
变量是用于在内存中存储数据的命名位置。可以将变量视为保存数据的容器,这些数据可以在后面程序中进行更改。例如,
1 | |
在这里,我们创建了一个名为number的变量。我们已将值 10 分配给变量 number。
您可以将变量视为用于存储书籍的袋子,并且可以随时替换里面的书籍。
1 | |
最初,它等于10。后来,它被更改为1.1。
注意:在Python中,我们实际上并未为变量分配值。相反,Python将对象(值)的引用提供给变量。
1.3.2 在python中为变量赋值
从上面的示例中可以看到,可以使用赋值运算符 = 为变量赋值。
示例1:声明和分配值给变量
1 | |
运行该程序时,输出为:
1 | |
在以上程序中,我们为变量website分配了一个值 apple.com 。然后,我们打印出分配给website的值,即 apple.com
注意:Python是一种类型推断语言,因此您不必显式定义变量类型。它会自动知道这 apple.com 是一个字符串,并将website变量声明为字符串。
示例2:更改变量的值
1 | |
运行该程序时,输出为:
1 | |
在上述程序中,我们最初已分配 apple.com 给website变量。然后,将值更改为 (cainiaojc.com)。
示例3:将多个值分配给多个变量
1 | |
如果我们想一次将相同的值分配给多个变量,我们可以这样做:
1 | |
第二个程序将字符串 same 同时分配给三个变量x,y和z。
常量
常量也是一种变量,只是其值一旦赋予后无法更改。可以将常量视为保存了以后无法更改的信息的容器。
您可以将常量视为一个用于存储一些书籍的袋子,这些书籍一旦放入袋子中就无法替换为别的书籍。
1.3.3 在python中为常量赋值
在Python中,常量通常是在模块中声明和分配的。在这里,模块是一个包含变量,函数等的新文件,该文件被导入到主文件中。在模块内部,用所有大写字母写的常量和下划线将单词分开。
示例3:声明值并将其分配给常量
创建一个constant.py:
1 | |
创建一个main.py:
1 | |
运行该程序时,输出为:
1 | |
在上面的程序中,我们创建一个 constant.py 模块文件。然后,将常量值分配给PI和GRAVITY。之后,我们创建一个 main.py 文件并导入constant 模块。最后,我们打印常数值。
注意:实际上,我们不在Python中使用常量。用大写字母命名它们是一种将其与普通变量分开的一种约定,但是,实际上并不能阻止重新分配。
1.3.4变量和常量的规则和命名约定
- 常量和变量名称应由小写字母(a 到 z)或大写字母(A 到 Z)或数字(0 到 9)或下划线(**_**)组成。例如:
1 | |
- 创建一个有意义的名称,例如,vowel比v更有意义
- 如果要创建具有两个单词的变量名,请使用下划线将它们分开。例如:
1 | |
- 使用可能的大写字母声明一个常量。例如:
1 | |
- 切勿使用!,@,#,$,%等特殊符号。
- 不要用数字开头的变量名
1.3.5 字面量
字面量是以变量或常量给出的原始数据。在python中,有多种类型的字面量。如下所示:
- 数字字面量
数字字面量是不可变的(不可更改)。数字字面量可以属于3种不同的数值类型:Integer,Float 和 Complex。
示例4:如何在python中使用数字字面量?
1 | |
运行该程序时,输出为:
1 | |
在上面的程序中:
- 我们将整数字面量分配给不同的变量。在这里,a是二进制字面量,b是十进制字面量,c是八进制字面量,d是十六进制字面量。
- 当我们打印变量时,所有字面量 都将转换为 十进制值。
- 10.5 和 1.5e2 是浮点字面量。1.5e2 用指数表示,等于 1.5 * 102。
- 我们为变量x分配了一个复数字面量 3.14j 。然后,我们使用虚数字面量(x.imag) 和 实数字面量(x.real)来创建复数的虚部和实部。
- 字符串字面量
字符串字面量是由引号括起来的一系列字符。我们可以对字符串使用单引号,双引号 或 三引号。并且,字符字面量是用单引号或双引号引起来的单个字符。
示例7:如何在python中使用字符串字面量?
1 | |
运行该程序时,输出为:
1 | |
在上述程序中,This is Python 是字符串字面量 和 C 是char字符字面量。在multiline_str中分配的带有三引号"""的值是多行字符串字面量。而 u"0dcnic0f6de" 是一个Unicode文本支持英语以外的字符,r"raw string" 是原始字符串字面量。
- 布尔字面量
布尔字面量可以具有两个值中的任何一个:True 或 False。
示例8:如何在python中使用布尔字面量?
1 | |
运行该程序时,输出为:
1 | |
在上面的程序中,我们使用了布尔字面量 True 和 False。在Python中,True 表示值为1,False 表示值为0。x的值为真,因为1 等于 True。y 的值为 False,因为1 不等于 False。类似地,我们可以使用数值表达式中的 True 和 False 作为值。a 的值是 5,因为我们加上True,它的值是 1 加 4。类似地,b 等于 10,因为我们把 0 和 10 相加。
- 特殊字面量
Python包含一个特殊字面量,即 None。我们使用它来指定尚未创建的字段。
示例9:如何在python中使用特殊字面量?
1 | |
运行该程序时,输出为:
1 | |
在上面的程序中,我们定义了一个 menu 函数。在 menu 内部,当我们将参数设置为 drink 时,它将显示 Available。并且,当参数为时 food,将显示 None。
- 字面量集
有四种不同的字面量集合:列表字面量,元组字面量,字典字面量 和 集合字面量。
示例10:如何在python中使用字面量集合?
1 | |
运行该程序时。输出为:
1 | |
在上面的程序中,我们创建了一个 fruits 列表,一个numbers元组,一个 alphabets 字典,alphabets字典的值带有为每个值指定的键,以及vowels 元音字母的集合。
1.4 python数据类型
1.4.1 python中的数据类型
Python中的每个值都有一个数据类型。由于在Python编程中一切都是对象,因此数据类型实际上是类,而变量是这些类的示例(对象)。
Python中有多种数据类型。下面列出了一些重要的类型。
1.4.2 python数字(Number)
整数、浮点数和复数都属于Python数字的范畴。在Python中,它们被定义为 int、float 和 complex类。
我们可以使用type()函数来判断一个变量或值属于哪个类。同样地,isinstance() 函数用于检查对象是否属于特定的类。
1 | |
输出量
1 | |
整数可以是任意长度,但受可用内存的限制。
浮点数最多可精确到 15 个小数位。整数 和 浮点由小数点分隔。1 是整数,1.0 是浮点数。
复数以 x + yj 形式书写,其中x是实部,y是虚部。这里有些示例。
1 | |
注意,float变量b被截断了。
1.4.3 python列表(List)
列表是项目的有序序列。它是Python中最常用的数据类型之一,非常灵活。列表中的项目允许不是同一类型。
声明列表非常简单。用逗号分隔的项目放在方括号内[ ]。
1 | |
我们可以使用切片运算符 [ ] 从列表中提取一个项目 或 一系列项目。注意,在Python中,索引从 0 开始。
1 | |
输出量
1 | |
列表是可变的,也就是说,列表元素的值可以更改
1 | |
输出量
1 | |
1.4.4 python元组(Tuple)
元组(Tuple)是项目的有序序列,与列表(List)相同。唯一的区别是元组是不可变的。元组一旦创建就不能修改。
元组用于写保护数据,通常比列表快,因为它们不能动态更改。
它在括号内 () 定义,其中各项之间用逗号分隔。
1 | |
我们可以使用切片运算符[]提取项目,但不能更改其值
1 | |
输出量
1 | |
1.4.5 python字符串
字符串是Unicode字符的序列。我们可以使用单引号或双引号来表示字符串。可以使用三引号 ''' 或 """ 来表示多行字符串。
1 | |
输出量
1 | |
就像列表和元组一样,切片运算符 [ ] 可以与字符串一起使用。但是,字符串是不可变的。
1 | |
输出量
1 | |
1.4.6 python集合(set)
set是唯一项的无序集合。Set 由用大括号 { } 括起来,并由逗号分隔的值的集合。集合中的项目是无序的
1 | |
输出量
1 | |
我们可以在两个集合上执行集合操作,例如 并集,交集。集具有唯一值。他们消除重复。
1 | |
输出量
1 | |
由于 set 是无序集合,因此索引没有意义。因此,切片运算符 [] 不起作用。
1 | |
1.4.7 python字典
字典是 键值对 的无序集合。
当我们拥有大量数据时,通常使用它。字典针对检索数据进行了优化。我们必须知道检索值的密钥。
在Python中,大括号 {} 内定义了字典,每一项都是形式为 key:value 。键 和 值 可以是任何类型。
1 | |
我们可以使用键来检索相应的值
1 | |
输出量
1 | |
1.4.8 数据类型转换
我们可以通过使用不同类型的转换功能,例如不同的数据类型之间进行转换 int(),float(),str() 等。
1 | |
从float 到 int的转换将截断该值(使其接近零)。
1 | |
字符串之间的转换必须包含兼容的值。
1 | |
我们甚至可以将一个序列转换为另一序列。
1 | |
要转换为字典,每个元素必须成对:
1 | |
1.5 python类型转换
1.5.1 类型转换
将一种数据类型(整数,字符串,浮点数等)的值转换为另一种数据类型的过程称为类型转换。Python有两种类型的类型转换。
- 隐式类型转换
- 显示类型转换
1.5.2 隐式类型转换
在隐式类型转换中,Python自动将一种数据类型转换为另一种数据类型。此过程不需要任何用户参与。
让我们看一个示例,其中Python促进将较低数据类型(整数)转换为较高数据类型(浮点数)以避免数据丢失。
示例1:将整数转换为浮点数
1 | |
当我们运行上面的程序时,输出将是:
1 | |
在上面的程序中
- 我们将两个变量num_int和num_flo 相加,并将值存储在变量num_new 中。
- 我们分别查看所有三个对象的数据类型。
- 在输出中,我们可以看到num_int的数据类型是 integer,num_flo的数据类型是一个float。
- 另外,我们可以看到num_new具有float数据类型,因为 Python 总是将较小的数据类型转换为较大的数据类型,以避免数据丢失。
现在,让我们尝试 一个字符串 和 一个整数 相加,并查看Python如何处理它。
示例2:字符串(较高)数据类型和整数(较低)数据类型的加法
1 | |
当我们运行上面的程序时,输出将是:
1 | |
在上面的程序中
- 我们两个变量num_int 和num_str相加。
- 从输出中可以看到,我们得到了 TypeError。在这种情况下,Python无法使用隐式转换。
- 但是,Python针对此类情况提供了一种解决方案,称为“显式转换”。
1.5.3 显式类型转换
在“显式类型转换”中,用户将对象的数据类型转换为所需的数据类型。我们使用像预定义函数 int(),float(),str()等进行显式类型转换。
这种转换类型也称为类型转换,因为用户强制转换(更改)对象的数据类型。
语法 :
1 | |
可以通过将所需的数据类型函数分配给表达式来完成类型转换。
示例3:使用显式转换将字符串和整数相加
1 | |
当我们运行上面的程序时,输出将是:
1 | |
在上面的程序中
- 我们num_str和num_int变量相加。
- 我们使用 int() 函数将num_str从 string(高)转换为 integer(低)类型来执行加法。
- 将num_str转换为整数后,Python可以对这两个变量进行相加。
- 最后,我们得到num_sum值 和 以及该值得数据类型为整数。
1.5.4 要记住的要点
- 类型转换是对象从一种数据类型到另一种数据类型的转换。
- 隐式类型转换由Python解释器自动执行。
- Python避免了隐式类型转换中的数据丢失。
- 显式类型转换也称为类型转换,用户使用预定义的函数转换对象的数据类型。
- 在类型转换中,当我们将对象强制为特定数据类型时,可能会发生数据丢失。
1.6 python输入,输出和导入
python提供了许多内置函数,这些函数可以在python提示符下随时使用
内置的函数例如 input() 和 print() 分别广泛用于标准输入和输出操作。让我们首先查看输出部分。
1.6.1 python使用print()函数输出
我们使用 print()函数将数据输出到标准输出设备(屏幕)。我们也可以将数据输出到文件中,这将在后面讨论
示例
1 | |
输出量
1 | |
下面给出另一个示例:
1 | |
输出量
1 | |
在第二个print()语句中,我们可以注意到在字符串和变量a的值之间添加了空格。这是默认设置,但是我们可以更改它。
print()函数的实际语法为:
1 | |
此处objects是要打印的值。
sep是值之间的分隔符。默认为空格字符。
在打印所有值之后,end 将被打印。默认为新行。
file 是打印值的对象,其默认值为 sys.stdout(屏幕)。 这是一个示例来说明这一点。
示例
1 | |
输出量
1 | |
1.6.2 输出格式
有时我们想格式化输出,使其看起来更方便阅读查看。这可以通过使用 str.format() 方法来完成。该方法对任何字符串对象都是可见的。
1 | |
在这里,花括号{}用作占位符。我们可以使用数字(元组索引)指定它们的打印顺序。
1 | |
输出量
1 | |
我们甚至可以使用关键字参数来格式化字符串。
1 | |
我们还可以像在C编程语言中使用 sprintf() 的旧样式一样格式化字符串。我们使用 % 运算符来完成此任务。
1 | |
1.6.3 python输入
到目前为止,我们的程序是静态的。变量的值已定义或硬编码到源代码中。
为了提供灵活性,我们可能希望从用户那里获取输入。在Python中,我们具有input()允许此功能的功能。的语法为input():
1 | |
prompt我们希望在屏幕上显示的字符串在哪里。它是可选的。
1 | |
在这里,我们可以看到输入的值10是一个字符串,而不是数字。要将其转换为数字,我们可以使用int()或float()函数。
1 | |
使用该eval()功能可以执行相同的操作。但是要eval进一步。如果输入是字符串,它甚至可以计算表达式
1 | |
1.6.4 python的导入
当我们的程序变得更大时,将其分解为不同的模块是一个好主意。
模块是包含Python定义和语句的文件。python模块具有文件名,并以扩展名 .py 结尾。
可以将模块内部的定义导入另一个模块 或 Python中的交互式解释器。我们使用 import 关键字来做到这一点。
例如,我们可以通过输入以下行来导入模块 math:
1 | |
我们可以通过以下方式使用该模块
1 | |
输出量
1 | |
现在,math模块内的所有定义都可以在我们的范围内使用。我们还可以使用from关键字仅导入一些特定的属性和函数。例如:
1 | |
导入模块时,Python 中使用sys.path会查看中定义的多个位置。它是目录位置的列表。
1 | |
我们也可以将自己的位置添加到此列表中。
1.7 python运算符
1.7.1 python中的运算符是什么
运算符是Python中执行算术或逻辑计算的特殊符号。运算符所操作的值称为操作数。
例如:
1 | |
在这里,+是执行加法的运算符。2和3是操作数,5是操作的输出。
1.7.2 算数运算符
算术运算符用于执行数学运算,例如加法,减法,乘法等。
| 操作符 | 含义 | 例 |
|---|---|---|
| + | 加 - 两个操作数相加或一元加 | x + y + 2 |
| - | 减 - 从左侧或一元减号,减去右侧操作数 | x-y- 2 |
| * | 乘 -将两个操作数相乘 | x * y |
| / | 除 - 将左边操作数除以右边操作数(结果总是为float) | x / y |
| % | 求模 -左操作数除以右操作数的余数 | x%y(x / y的余数) |
| // | 取整除 - 返回商的整数部分(向下取整) | x // y |
| ** | 幂 - 返回x的y次幂 | x ** y(x的y次幂) |
示例1:Python中的算术运算符
示例
1 | |
运行该程序时,输出为:
1 | |
1.7.3 比较运算符
比较运算符用于比较值。它返回True或False根据条件返回。
| 操作符 | 含义 | 例 |
|---|---|---|
| > | 大于-如果左操作数大于右操作数,则为True | x> y |
| < | 小于-如果左操作数小于右操作数,则为True | x <y |
| == | 等于-如果两个操作数相等,则为True | x == y |
| != | 不等于-如果操作数不相等则为True | x!= y |
| >= | 大于或等于-如果左操作数大于或等于右,则为True | x> = y |
| <= | 小于或等于-如果左操作数小于或等于右,则为True | x <= y |
示例2:Python中的比较运算符
示例
1 | |
输出结果
1 | |
1.7.4 逻辑运算符
逻辑运算符是and,or,not运营商。
| 操作符 | 含义 | 例 |
|---|---|---|
| and | 如果两个操作数都为真,则为真 | x和y |
| or | 如果任何一个操作数为真,则为真 | x或y |
| not | 如果操作数为false,则为True(对操作数进行补充) | 不是x |
示例3:Python中的逻辑运算符
示例
1 | |
输出结果
1 | |
这是这些运算符的真值表。
1.7.5 位运算符
按位运算符作用于操作数,就好像它们是二进制数字的字符串一样。它们一点一点地运行,因此得名。
例如,2是10二进制,7是111。
在下表中:令x= 10(0000 1010二进制)和y= 4(0000 0100二进制)
| 操作符 | 含义 | 例 |
|---|---|---|
| & | 按位与 | x&y = 0(0000 0000) |
| | | 按位或 | x | y = 14(0000 1110) |
| ~ | 按位非 | 〜x = -11(1111 0101) |
| ^ | 按位异或 | x ^ y = 14(0000 1110) |
| >> | 按位右移 | x >> 2 = 2(0000 0010) |
| << | 按位左移 | x << 2 = 40(0010 1000) |
1.7.6 赋值运算符
在Python中使用赋值运算符为变量赋值。
a = 5是一个简单的赋值运算符,它将右边的值5分配给左边的变量a。
Python中有许多类似的复合运算符,a += 5它们会添加到变量中,然后再分配给它们。等同于a = a + 5。
| 操作符 | 示例 | 等同 |
|---|---|---|
| = | x = 5 | x = 5 |
| += | x + = 5 | x = x + 5 |
| -= | x-= 5 | x = x-5 |
| *= | x * = 5 | x = x * 5 |
| /= | x / = 5 | x = x / 5 |
| %= | x%= 5 | x = x%5 |
| //= | x // = 5 | x = x // 5 |
| **= | x ** = 5 | x = x ** 5 |
| &= | x&= 5 | x = x&5 |
| |= | x | = 5 | x = x | 5 |
| ^= | x ^ = 5 | x = x ^ 5 |
| >>= | x >> = 5 | x = x >> 5 |
| <<= | x << = 5 | x = x << 5 |
1.7.7 特殊运算符
Python语言提供了一些特殊类型的运算符,例如身份运算符或成员资格运算符。下面通过示例对其进行描述。
身份运算符
is和is not是Python中的身份运算符。 它们用于检查两个值(或变量)是否位于内存的同一部分。 两个相等的变量并不意味着它们是相同的。
| 操作符 | 含义 | 例 |
|---|---|---|
| is | 如果操作数相同,则为真(引用同一对象) | x为真 |
| is not | 如果操作数不相同,则为真(不引用同一对象) | x不是真 |
示例4:Python中的身份运算符
示例
1 | |
输出结果
1 | |
在这里,我们看到x1和y1是相同值的整数,因此它们既相等又相同。x2和y2(字符串)的情况相同。
但是x3和y3是列表。它们是相等的但不相同。这是因为尽管它们相等,但解释器还是将它们分别定位在内存中。
1.7.8 成员运算符
in和not in是Python中的成员操作符。它们用于测试在序列(字符串,列表,元组,集合和字典)中是否找到值或变量。
在字典中,我们只能测试键的存在,而不是值。
| 操作员 | 含义 | 例 |
|---|---|---|
| in | 如果在序列中找到值/变量,则为真 | 5 in x |
| not in | 如果在序列中未找到值/变量,则为真 | 5 not in x |
示例5:Python中的成员资格运算符
示例
1 | |
输出结果
1 | |
这里,'H'在x中,但'hello'在x中不存在(请记住,Python是区分大小写的)。类似地,1是键值,而a是字典y中的值,因此y中的a返回False。
2. python流程控制
2.1 python if...else语句
2.1.1 python if语句语法
python语句语法
1 | |
如果文本表达式为False,则不执行该语句。
在Python中,if语句的主体由缩进指示。主体以缩进开始,直到第一条未缩进的语句时结束。
Python将非零值作为True。None 和 0 被视作为False。
示例
1 | |
运行该程序时,输出为:
1 | |
在上面的示例中,num > 0 是测试表达式。
if语句中,仅当其值为True时才执行的主体。
当变量num等于 3 时,测试表达式为 true,将执行 if主体内部 的语句。
如果变量num等于-1,则测试表达式为false,将跳过 if主体内部 的语句。
print()语句位于 if块之外(未缩进)。因此,无论测试表达式如何,都将执行它。
2.1.2 python if ... else 语句
1 | |
if ... else语句评估 test expression 并且if语句仅在测试条件为 True 时才执行主体。
如果条件为 False,则执行 else的主体。缩进用于分隔块。
if ... else 的示例
示例
1 | |
输出结果
1 | |
在上面的示例中,当 num 等于3时,测试表达式为 true,并且if的主体被执行,else的主体被跳过。
如果num等于-5,则测试表达式为false,执行else的主体,并且跳过if的主体。
如果num等于0,则测试表达式为true,if的主体被执行,else的主体被跳过。
2.1.3 python if ... elif ... else语句
if ... elif ... else的语法
1 | |
elif是else if的缩写。它允许我们检查多个表达式。如果If的条件为False,则检查下一个elif块的条件,依此类推。
如果所有条件都为False,则执行else的主体。
if...elif...else根据条件,在几个块中仅执行一个块。
if块只能有一个else块。但是它可以有多个elif块。
示例
1 | |
当变量num为正时,输出:正数 。
如果num等于0,输出:零 。
如果num为负数,输出:负数 。
2.1.4 python嵌套if语句
我们可以在另一个if...elif...else语句中包含一个if...elif...else语句。这在计算机编程中称为嵌套。
这些语句中的任何数目都可以彼此嵌套。缩进是弄清楚嵌套级别的唯一方法。它们可能会造成混淆,因此除非有必要,否则必须避免使用它们。
示例
1 | |
输出1
1 | |
输出2
1 | |
输出3
1 | |
2.2 python for循环
2.2.1 什么是Python中的for循环?
Python中的for循环用于迭代序列(list,tuple,string)或其他可迭代对象。在序列上进行迭代称为遍历。
for循环的语法
1 | |
在此,val是在每次迭代中获取序列内项目值的变量。
循环继续直到我们到达序列中的最后一项。使用缩进将for循环的主体与其余代码分开。
示例:Python for循环
示例
1 | |
当您运行程序时,输出将是:
1 | |
2.2.2 range函数
我们可以使用range()函数生成数字序列。range(10)会产生0到9之间的数字(10个数字)。
我们还可以将开始,停止和步长定义为range(start, stop,step_size)。如果未提供,则step_size默认为1。
range对象在某种意义上是“惰性的”,因为它不会在我们创建它时生成它“包含”的所有数字。但是它不是迭代器,它支持in、len和getitem操作。
此函数不将所有值存储在内存中;这将是低效的。因此,它会记住开始、停止、步长,并在运行中生成下一个数字。
要强制此函数输出所有项目,可以使用函数list()。
以下示例将演示了这一点。
示例
1 | |
输出结果
1 | |
我们可以在for循环中使用 range() 函数来迭代数字序列。它可以与len()函数结合使用索引来遍历序列。这是一个示例。
1 | |
运行该程序时,输出为:
1 | |
2.2.3 带有else的循环
for循环也可以有一个可选的else块。
如果for循环中使用的序列中的项耗尽,则执行else部分。
break关键字可用于停止for循环。在这种情况下,else部分将被忽略。
因此,如果没有发生中断,则运行for循环的else部分。
这是一个示例来说明这一点。
示例
1 | |
运行该程序时,输出为:
1 | |
在这里,for循环将打印列表中的项目,直到循环用尽。当for循环用尽时,它执行else代码块并输出 "没有剩余的项目"。
for...else语句可与break关键字一起使用,以便仅在未执行break关键字时运行else块。让我们举个示例:
示例
1 | |
输出结果
1 | |
2.3 python while循环
2.3.1 python中while循环的语法
1 | |
在while循环中,首先检查测试表达式。仅当test_expression计算结果为True时,才输入循环的主体。一次迭代后,再次检查测试表达式。这个过程一直持续到test_expression评估结果为False为止。
在Python中,while循环的主体是通过缩进确定的。
主体以缩进开始,第一条未缩进的线标记结束。
Python将任何非零值解释为True。None并且0被解释为False。
示例
1 | |
运行该程序时,输出为:
1 | |
在上面的程序中,只要我们的计数器变量i小于或等于n(在我们的程序中为10),则测试表达式为True。
我们需要在循环体内增加计数器变量的值。这是非常重要的(千万不要忘记)。否则,将导致无限循环(永无止境的循环)。
最后,显示结果。
2.3.2 while 与 else循环
与for循环相同,而while循环也可以具有可选else块
如果while循环中的条件求值为False,则执行else该部分
while循环可以使用break语句终止。在这种情况下,该else语句将被忽略。因此,如果没有break中断并且条件为False,则while循环的else语句将运行
示例
1 | |
输出结果
1 | |
在这里,我们使用计数器变量来打印字符串 内部循环 三次。
在第四次迭代中,while中条件变为False。因此,该else部分会被执行。
2.4 python break和continue
2.4.1 python中break和continue的作用是什么
在Python中,break和continue语句可以更改常规循环的流程。
循环遍历代码块,直到测试表达式为假,但有时我们希望在不检查测试表达式的情况下终止当前迭代甚至整个循环,那么break和continue语句在这些情况下就可以使用。
2.4.2 python break语句
break语句终止包含它的循环。程序的控制权在循环体之后立即传递到该语句。
如果该break语句在嵌套循环内(另一个循环内的循环),则该break语句将终止最里面的循环。
break语法
1 | |
示例
1 | |
输出结果
1 | |
在这个程序中,我们遍历“string”序列。我们检查这个字母是不是i,这样我们就可以跳出循环。因此,我们在输出中看到,直到我打印出来的所有字母。之后,循环终止。
2.4.3 python continue语句
continue语句仅在当前迭代时用于跳过循环内的其余代码。循环不会终止,但会继续进行下一个迭代。
continue语法
1 | |
示例
1 | |
输出结果
1 | |
这个程序与上面的示例相同,只是将break语句替换为continue。我们继续循环,如果字符串是i,则不执行其余的块。因此,我们在输出中看到除了i之外的所有字母都被打印出来了。
2.5 python pass语句
2.5.1 什么是python中的pass语句
在Python编程中,pass语句为空语句。在Python中,注释和pass语句之间的区别在于,尽管解释器完全忽略注释,而pass不会被忽略
但是,执行传递时没有任何反应。结果为无操作(NOP)
pass语法
1 | |
我们通常将其用作占位符。
假设我们有一个尚未实现的循环或函数,但我们想在将来执行实现它。他们不能有一个空的主体,解释器将给出错误。因此,我们使用该pass语句构造一个不执行任何操作的主体
示例
1 | |
我们也可以在空函数或类中执行相同的操作
1 | |
1 | |
3 python函数
3.1 python函数
3.1.1 python中的函数是什么
在Python中,函数是一组执行特定任务的相关语句。
函数有助于将我们的程序分解为较小的模块。随着我们的项目越来越大,函数使其变得更加有组织和易于管理。
此外,它避免了重复写相同的代码,函数使代码可重复使用。
函数语法
1 | |
上面显示的是由以下组件组成的函数定义。
- def标记函数头开始的关键字。
- 用于唯一标识函数的函数名称。函数命名遵循在Python中编写标识符的相同规则。
- 通过其将值传递给函数的参数。它们是可选的。
- 冒号(:)标记函数头的结尾。
- 可选的文档字符串(docstring),用于描述函数的函数。
- 组成函数体的一个或多个有效python语句。语句必须具有相同的缩进级别(通常为4个空格)。
- 可选的return语句,用于从函数返回值。
示例
1 | |
如何在python中调用函数?
定义函数后,我们可以从另一个函数,程序甚至Python提示符中调用它。要调用函数,我们只需键入带有适当参数的函数名称即可。
1 | |
注意:尝试在带有函数定义的python程序中运行以上代码,以查看输出
示例
1 | |
3.1.2 Docstrings(文档字符串)
函数头之后的第一个字符串称为docstring,是文档字符串的缩写。简要说明了函数的作用。
尽管是可选的,但文档是一种良好的编程习惯。除非您记得去年今天的晚餐时间和晚餐吃什么,否则请务必记录注释您的代码。
在上面的示例中,我们在函数标头的正下方有一个文档字符串。我们通常使用三引号将文档字符串扩展为多行。该字符串可作为__doc__函数的属性供我们使用。
例如:
尝试将以下内容运行到Python shell中以查看输出。
1 | |
3.1.3 return语句
return语句用于退出函数并返回到调用函数的位置。
返回语法
1 | |
该语句可以包含一个表达式,该表达式将被求值并返回值。如果该语句中没有表达式,或者return语句本身不存在于函数中,则该函数将返回None对象。
例如
1 | |
return示例
1 | |
输出结果
1 | |
3.1.4 变量的作用域和生命周期
变量的作用域是程序中可以识别该变量的部分。从函数外部看不到在函数内部定义的参数和变量。因此,它们具有本地作用域。
变量的生命周期是变量在内存中退出的时间。函数内部变量的生命周期与函数执行的时间一样长。
一旦我们从函数返回,它们就会被销毁。因此,函数无法记住其先前调用中的变量值。
这是一个示例,用于说明函数内部变量的生命周期。
示例
1 | |
输出结果
1 | |
在这里,我们可以看到x的初始值为20。即使函数my_func()将x的值更改为10,它也不会影响函数外部的值。
这是因为函数内部的变量x与函数外部的x变量不同。尽管它们具有相同的名称,但是它们是两个具有不同作用域的不同变量。
另一方面,从外部可以看到函数外部的变量。它们具有全局作用域,也就是函数内外部都可以使用该全局变量。
我们可以从函数内部读取这些值,但不能更改(写入)它们。如果要在函数外部修改变量的值,必须使用关键字global,将它们声明为全局变量。
3.2 匿名函数(Lambda函数)
3.2.1 什么是python中的lambda函数
在Python中,匿名函数是没有定义名称的函数
虽然def在Python中使用关键字定义了普通函数,但使用关键字定义了匿名函数lambda。
因此,匿名函数也称为lambda函数。
3.2.2 如何在python中使用lambda函数
- python中lambda函数语法
1 | |
Lambda函数可以具有任意数量的参数,但只能有一个表达式。表达式被求值并返回。Lambda函数可在需要函数对象的任何地方使用。
示例
1 | |
输出
1 | |
在上面的程序中,lambda x: x * 2是lambda函数。这里x是参数,x * 2是求值和返回的表达式。
这个函数没有名字。它返回一个函数对象,该对象被分配给标识符double。我们现在可以把它叫做普通函数。下面声明
1 | |
等同于:
1 | |
- 在python中使用lambda函数
当我们临时需要匿名函数时,我们使用lambda函数。
在Python中,我们通常将其用作高阶函数的参数(该函数将其他函数作为arguments)。lambda函数可以与filter(), map()等内置函数一起使用
lambda与filer()一起使用的示例
1 | |
输出
1 | |
lambda与map()一起使用的示例
在Python中的map()函数接受一个函数和一个列表。
使用列表中的所有项调用该函数,并返回一个新列表,其中包含该函数为每个项返回的项。
这是使用map()函数将列表中所有项目翻倍的示例。
示例
1 | |
输出
1 | |
3.3 python全局,局部和非局部变量
3.3.1 全局变量
在Python中,在函数外部或全局范围内声明的变量称为全局变量。这意味着可以在函数内部或外部访问全局变量。
让我们看一下如何在Python中创建全局变量的示例。
示例1:创建一个全局变量
1 | |
输出
1 | |
在上面的代码中,我们将x创建为全局变量,并定义了foo()来打印全局变量x。最后,我们调用foo()将打印x值的。
如果要在函数内更改x的值怎么办?
示例
1 | |
输出
1 | |
输出显示了一个错误,因为Python将x视为一个局部变量,并且x也没有在foo()中定义。
3.3.2 局部变量
在函数体内或局部范围内声明的变量称为局部变量
示例2:访问范围外的局部变量
1 | |
输出
1 | |
输出显示一个错误,因为我们试图在全局范围内访问一个局部变量y,而局部变量只在foo()或局部范围内工作。
让我们看一个有关如何在Python中创建局部变量的示例。
示例3:创建局部变量
通常,我们在函数内部声明一个变量以创建局部变量。
1 | |
当我们运行代码时,它将输出
1 | |
3.3.3 全局和局部变量
示例4:在同一代码中使用全局变量和局部变量
1 | |
将输出
1 | |
在上面的代码中,我们将x声明为全局变量,将y声明为foo()中的局部变量。然后,我们使用乘法运算符*来修改全局变量x,并同时输出x和y。
在调用foo()之后,x的值就变成了global global,因为我们使用x * 2来打印两次global。然后,我们打印局部变量y的值,即局部变量。
示例5:具有相同名称的全局变量和局部变量
1 | |
输出
1 | |
在上面的代码中,我们对全局变量和局部变量使用了相同的名称x。当我们打印相同的变量时,会得到不同的结果,因为变量是在两个作用域中声明的,即foo()内的局部作用域和foo()外的全局作用域。
当我们在foo()中打印变量时,它输出的是local x: 10。这称为变量的局部作用域。
同样,当我们在foo()外部打印变量时,它会输出global x: 5。这称为变量的全局范围。
3.3.4 非局部变量
非局部变量用于未定义局部作用域的嵌套函数。这意味着该变量既不能在局部范围内,也不能在全局范围内。
让我们看一下如何在Python中创建全局变量的示例。
我们使用nonlocal关键字创建非局部变量。
示例6:创建一个非局部变量
1 | |
输出
1 | |
在上面的代码中,有一个嵌套函数inner()。 我们使用nonlocal关键字创建一个非局部变量。 inner()函数在另一个函数external()的范围内定义。
3.4 python模块
3.4.1 python中的模块是什么
模块是指包含Python语句和定义的文件。
包含Python代码的文件,例如:example.py,称为模块,其模块名称为example。
我们使用模块将大型程序分解为可管理的小型文件。此外,模块提供了代码的可重用性。
我们可以在模块中定义最常用的函数并将其导入,而不是将其定义复制到其他程序中。
让我们创建一个模块。输入以下内容并将其另存为example.py。
1 | |
这里,我们在一个名为example的模块中定义了一个add()函数。该函数接受两个数字并返回他们的和
3.4.2 如何在python中导入模块
我们可以将模块内部的定义导入另一个模块或Python中的交互式解释器。
我们使用import关键字来做到这一点。要导入我们先前定义的模块,example我们在Python提示符下键入以下内容。
1 | |
这不会example直接在当前符号表中输入定义的功能名称。它仅在example此处输入模块名称。
使用模块名称,我们可以使用点. 运算符访问函数。例如:
1 | |
Python有大量可用的标准模块。这些文件位于Python安装位置内的Lib目录中。
可以像导入用户定义的模块一样导入标准模块。
有多种导入模块的方法。它们列出如下。
- python导入语句
示例
1 | |
运行该程序时,输出为:
1 | |
- 重命名导入
示例
1 | |
我们已将math模块重命名为m。在某些情况下,这可以节省我们的书写时间。
请注意,该名称math在我们的范围内无法识别。因此,math.pi无效的,而m.pi是正确的使用方式。
- python from ... import语句
示例
1 | |
我们仅从模块导入属性pi。
在这种情况下,我们不使用点运算符。我们可以如下导入多个属性。
1 | |
- 导入所有名称
我们可以使用以下构造从模块导入所有名称(定义)
示例
1 | |
我们从数学模块中导入了所有定义。这使得除带下划线的beginnig之外的所有名称在我们的范围内可见。
导入带有星号(*)符号的所有内容都不是一种好的编程习惯。这可能导致标识符重复定义。这也会影响我们代码的可读性。
- python模块搜索路径
导入模块时,Python会在多个位置进行检查。解释器首先寻找一个内置模块,然后(如果找不到)进入定义的目录列表sys.path。搜索按此顺序进行。
当前目录。
PYTHONPATH (带有目录列表的环境变量)。
与安装有关的默认目录。
1 | |
- 重新加载模块
Python解释器在会话期间仅导入一次模块。这使事情更有效率。这是一个示例,说明其工作原理。
假设在名为的模块中有以下代码my_module。
1 | |
现在我们看到了多次导入的效果
1 | |
我们可以看到我们的代码只执行了一次。这说明我们的模块仅导入了一次。
现在,如果我们的模块在程序执行过程中发生了变化,我们将不得不重新加载它。一种方法是重启解释器。但这并没有太大帮助。
Python提供了一种简洁的方法。我们可以使用模块reload()内部的函数imp来重新加载模块。这是怎么做的。
1 | |
- dir()内置函数
我们可以使用dir()函数找出在模块内部定义的名称。
例如,我们在开始的模块example中定义了一个add()函数。
1 | |
在这里,我们可以看到一个已排序的名称列表(以及add)。以下划线开头的所有其他名称都是与模块关联的默认Python属性(我们自己没有定义它们)。
例如,__name__属性包含模块的名称。
1 | |
可以使用不带任何参数的dir()函数找出当前名称空间中定义的所有名称。
1 | |
3.5 python包(package)
3.5.1 什么是包(package)?
我们通常不会把所有的文件都存储在同一个地方。我们使用一个组织良好的目录层次结构,以方便访问。
相似的文件保存在同一目录中,例如,我们可以将所有歌曲保留在“music”目录中。与此类似,Python具有用于目录的软件包和用于文件的模块。
随着我们的应用程序规模越来越大,带有许多模块,我们将相似的模块放在一个包中,而将不同的模块放在不同的包中。这使项目(程序)易于管理且概念清晰。
类似地,由于目录可以包含子目录和文件,因此Python程序包可以具有子程序包和模块。
目录必须包含一个名为 init.py 的文件,Python才能将其视为一个包。该文件可以保留为空,但是我们通常将该程序包的初始化代码放入此文件中。
这是一个实例。假设我们正在开发一个游戏,则可能的包和模块组织如下图所示。
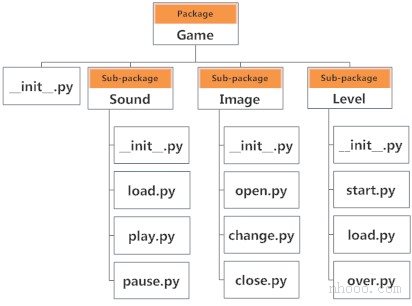
3.5.2 从包中导入模块
我们可以使用点(.)运算符从包中导入模块。
例如,如果要在上面的示例中导入 start 模块,请按以下步骤完成。
1 | |
现在,如果该模块包含名为select_difficulty()的函数,我们必须使用全名来引用她
1 | |
如果这个构造看起来很冗长,我们可以按以下方式导入不带包前缀的模块。
1 | |
现在,我们可以简单地如下调用该函数。
1 | |
仅将所需的函数(或类 或变量)从包中的模块中导入的另一种方法如下。
1 | |
现在我们可以直接调用此函数。
1 | |
尽管比较简单,但不建议使用此方法。使用完整的命名空间可避免混淆,并防止两个相同的标识符名称冲突
4 python文件操作
4.1 python文件I/O
4.1.1 什么是文件
文件是磁盘上用于存储相关信息的命名位置。它用于将数据永久存储在非易失性存储器(例如硬盘)中。
由于随机存取存储器(RAM)易失,当计算机关闭时会丢失其数据,因此我们将文件用于将来的数据使用。
当我们要读取或写入文件时,我们需要先打开它。完成后,需要将其关闭,以便释放与文件绑定的资源。
因此,在Python中,文件操作按以下顺序进行。
打开文件
读取或写入(执行操作)
关闭文件
4.1.2 如何打开文件
python具有内置函数open()来打开文件。此函数返回文件对象,也称为句柄,因为它用于相应的读取或修改文件
1 | |
我们可以在打开文件时指定模式。在模式下,我们指定是要读取'r',写入'w'还是追加'a'到文件。我们还指定是否要以文本模式或二进制模式打开文件。
默认设置是在文本模式下阅读。在这种模式下,当从文件中读取时,我们会得到字符串。
另一方面,二进制模式返回字节,这是处理非文本文件(如图像或exe文件)时要使用的模式。
python文件模式
| 模式 | 描述 |
|---|---|
| 'r' | 打开文件进行读取。(默认) |
| 'w' | 打开文件进行写入。如果不存在则创建一个新文件,或者如果存在将其截断 |
| 'x' | 打开文件以进行独占创建。如果文件已经存在,则操作失败。 |
| 'a' | 打开以在文件末尾追加而不截断。如果不存在,则创建一个新文件 |
| 't' | 以文本模式打开。(默认) |
| 'b' | 以二进制模式打开 |
| '+' | 打开文件进行更新(读取和写入) |
截断:清空文件内容,从头开始写入
1 | |
与其他语言不同,该字符'a'在使用ASCII(或其他等效编码)进行编码之前不会暗示数字97 。
此外,默认编码取决于平台。在Windows中,'cp1252'但是'utf-8'在Linux中。
因此,我们也不能依赖默认编码,否则我们的代码在不同平台上的行为会有所不同。
因此,在以文本模式处理文件时,强烈建议指定编码类型。
1 | |
4.1.3 如何使用python关闭文件
完成对文件的操作后,我们需要正确关闭文件
关闭文件将释放与该文件绑定的资源,并且使用close()方法完成 。
Python有一个垃圾收集器来清理未引用的对象,但是,我们绝对不能依靠它来关闭文件。
1 | |
这种方法并不完全安全。如果对文件执行某些操作时发生异常,则代码将退出而不关闭文件。
一种更安全的方法是使用try ... finally块
1 | |
这样,我们可以保证即使引发异常也可以正确关闭文件,从而导致程序流停止。
最好的方法是使用with语句。这样可以确保在with退出内部块时关闭文件。
我们不需要显式调用该close()方法。它是在内部完成的。
1 | |
4.1.4 如何在python中读取文件
要使用Python读取文件,我们必须以读取模式打开文件。
有多种方法可用于此目的。我们可以使用该read(size)方法读取大小数据。如果未指定size参数,它将读取并返回到文件末尾。
1 | |
我们可以看到,read()方法将换行符返回为''。到达文件末尾后,我们将在进一步阅读时得到空字符串。
我们可以使用seek()方法更改当前文件的光标(位置)。同样,tell()方法返回我们的当前位置(以字节数为单位)。
1 | |
我们可以使用for循环逐行读取文件。这既高效又快速
1 | |
文件本身的行具有换行符''。
此外,print()结束参数在打印时避免了两行换行。
或者,我们可以使用readline()方法读取文件的各个行。此方法读取文件,直到换行符为止,包括换行符。
1 | |
最后,该readlines()方法返回整个文件的其余行的列表。当到达文件结尾(EOF)时,所有这些读取方法都将返回空值。
1 | |
4.1.5Python文件方法
文件对象有多种可用方法。其中一些已在以上示例中使用。
这是文本模式下方法的完整列表,并带有简要说明。
python文件方法
| 方法 | 作用 |
|---|---|
close() |
关闭文件 |
detach() |
从缓冲区返回分离的原始流(raw stream) |
fileno() |
从操作系统的角度返回表示流的数字 |
flush() |
刷新内部缓冲区 |
isatty() |
返回文件流是否是交互式 |
read() |
返回文件内容 |
readable() |
返回是否能够读取文件流 |
readline() |
返回文件中的一行 |
readlines() |
返回文件中的行列表 |
seek() |
更改文件位置 |
seekable() |
返回文件是否允许我们更改文件位置 |
tell() |
返回当前文件位置 |
truncate() |
把文件调整为指定的大小 |
writeable() |
返回是否能够写入文件 |
write() |
把指定的字符串写入文件 |
writelines() |
把字符串列表写入文件 |