AI大语言模型
1. 什么是AIGC
- AIGC:AI Generated Content,AI生成内容
- generative ai:生成式ai
- 生成式ai所生成内容就是AIGC
AI、机器学习、监督学习、深度学习、生成式AI、大语言模型、无监督模型、强化学习之间的关系
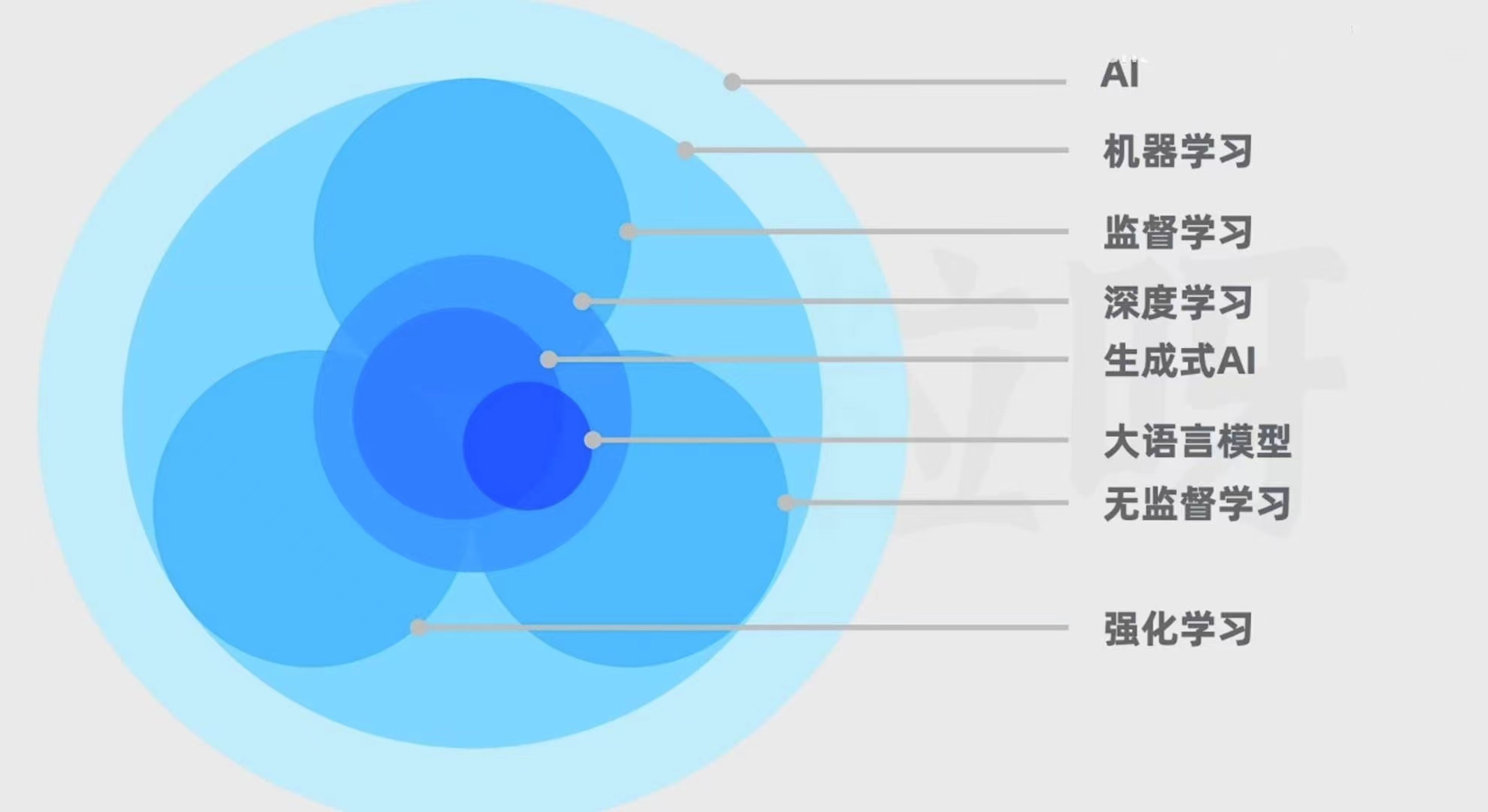
AI(Artificial Intelligence):人工智能,旨在让计算机系统去模拟人类的智能 ,从而解决问题和完成任务
机器学习(Machine Learning):AI的一个子集,不需要人类去做显式编程,而是通过算法去自行识别和改进,去识别模式、做出预测和抉择
- 显式编程:如果我们通过代码告诉电脑,图片里面有红色说明是玫瑰,有黄色说明是向日葵
- 机器学习:给电脑大量玫瑰和向日葵图片,让电脑自行识别模式,总结规律,从而对没见过的图片进行判断。这就是机器学习
- 机器学习领域下有若干分支,包括
监督学习、无监督学习、强化学习。
监督学习:机器学习算法会接受有标签的训练数据。每个训练数据点都既包括输入特征,也包括期望的输出值。
- 标签:期望的输出值
- 算法的目标:学习输入和输出之间的映射关系,从而在给出新的输入特征后能够准确预测出相应的输出值
- 举例:经典的监督学习任务包括分类、回归
- 分类:把数据划分为不同的类别。比如,拿一堆猫猫狗狗的照片,和照片对应的"猫" “狗"标签进行训练,让模型根据没见过的照片预测是猫还是狗
- 回归:对数值进行预测。比如,拿一些房子特征的数据,比如面积、卧室数、是否带阳台等,和相应的房价作为标签进行训练然后让模型根据没见过房子的特征预测房价
无监督学习:学习的内容是没有标签的,算法的任务是自主发现数据里的模式和规律。经典的无监督学习任务包括聚类。比如,拿一堆新闻文章,让模型根据主题或内容的特征,自主把相似文章进行组织
- 聚类:把数据进行分组。
强化学习:让模型在环境里采取行动,获得结果反馈,从反馈里学习,从而能在给定情况下采取最佳行动,来最大化奖励或最小化损失。跟训小狗类似,刚开始时小狗随心所欲做出很多动作,但随着与训犬师的互动,小狗发现某些动作会获得零食,某些动作会获得惩罚。通过观察动作和奖惩之间的联系,小狗的行为会逐渐接近训犬师的期望。
深度学习:不属于
监督学习、无监督学习或强化学习,他是机器学习的一个方法,核心在于使用人工神经网络,模仿人脑处理信息的方式,通过层次化的方法,提取和表示数据的特征。神经网络由许多基本的计算和存储单元组成,这些单元被称为神经元,这些神经元通过层层连接来处理数据,并且深度学习往往有很多层,因此称为”深度“。比如要识别一张小猫的照片,数据首先传入到输入层(就像人类的眼睛看到图片),之后数据通过多个隐藏层,每一层都会对数据进行一些复杂的数学运算,来帮助计算机理解图片中的特征,例如小猫的耳朵、眼睛等等。最后,计算机会给出一个答案,表示这是否是一张小猫的图片- 神经网络可以用于
监督学习、无监督学习、强化学习,所以深度学习不属于他们的子集。 - 生成式AI是深度学习的一个应用,它利用神经网络来识别现有内容的模式和结构,学习生成新的内容。内容形式可以是文本、图片、音频等等
- 大语言模型(Large Language Model, LLM)也是深度学习的一种应用,专门用于进行自然语言处理任务。包括模型输入、训练数据、模型输出
- 不是所有的生成式AI都是大语言模型,例如扩散模型
- 扩散模型:扩散模型首先定义了一个由数据分布逐步转化为高斯噪声分布的过程(正向扩散),这一过程可以视为一系列逐渐添加噪声的步骤。随后,模型学习如何执行这一过程的逆操作,即从纯粹的噪声开始,通过一系列逆步骤逐步“去噪”,最终生成接近原始数据分布的样本(反向扩散)。
- 而是否所有的大语言模型都是生成式AI,这也存在些许争议。因为有些大语言模型因为其架构特点,不适合文本生成。
2. 什么是大语言模型
大语言模型(Large Language Model, LLM)是用于做自然语言相关任务的深度学习模型,给模型一些文本输入,他能进行相应的文本输出大语言模型首先需要通过大量文本进行无监督学习。借助海量的训练文本数据,模型能更多了解单词与上下文之间的关系,从而能更好的了解文本的含义,并生成更准确的预测
大语言模型的大,不止是指训练数据量大,而是参数数量巨大。
参数:模型内部的变量,可以理解为是模型在训练过程中学到的知识。参数决定了模型如何对输入数据作出反应,从而决定模型的行为。(GPT(Generative Pre-trained Transformer,Transformer是其中的关键)-1参数有1.17亿个,GPT-2参数有15亿个,而GPT-3的参数又增长到1750亿个) 。
在Transformer被提出之前,语言模型的主要架构是循环神经网络(Recurrent Neural Network)。RNN逐字处理,每一步取决于先前的隐藏状态和当前的输入,因此无法并行运算,训练效率低。而且RNN不适合长文本训练。词之间距离越远,前面对后面的影响越弱,所以它难以得到长距离的语义关系
Transformer有能力学习输入序列里所有词的相关性和上下文,不会受到短时记忆的影响,因为Transformer有注意力机制。简单来说,Transformer在处理每个词的时候,不仅会注意这个词本身,以及它附件的词,还会去注意输入序列里所有其他的词,然后给予每个词不一样的注意力权重。权重是模型在训练过程中通过大量文本习得的。因此Transformer有能力知道当前这个词和其他词之间的相关性有多强,然后去专注于输入里真正重要的部分,即使两个词的距离很远,Transformer依然能捕获到它们之间的依赖关系。
Transformer在把每个词输入给神经网络前,除了会对词进行嵌入,转换成向量,也就是把词各用一串数字表示,还会把每个词在句子中的位置,也各用一串数字表示,添加到输入序列的表示中,然后把这个结果给神经网络,这样模型既能理解每个词的实际意义,又能捕获词在句子中的位置,从而理解不同词之间的顺序关系。借助位置编码,词可以不按顺序输入给Transformer,模型可以同时处理输入序列里的所有位置,而不需要像RNN那样依次处理。在计算时,每个输出都可以独立地计算,不需要等待其他位置的计算结果,这大大提升了训练速度。
3. Transformer
Transformer由两个核心部分组成:编码器(Enconder)和解码器(Decoder)
工作原理:
编码器部分:
- 假如我们想要将一个英文橘子转化为法语,比如输入:
She is in a restaurant,输入的文本首先会被token化,也就是先把输入拆分成各个token:sheisinarestaurant。取决于不同的token化方法,短单词可能每个词是一个token,长单词可能被拆成多个token。每个token会被一个整数数字表示,这个数字被叫做token ID。这样做是因为计算机内部无法储存文字,任何字符和字符最终都得用数字来表示。有了数字表示的输入文本后,再把它传入嵌入层。 - 通过编码器获得词向量之后,下一步是对向量进行位置编码,然后把得到的结果传给编码器。模型既可以理解每个词的意义,又可以捕捉词在句子中的位置,从而理解不同词之间的顺序关系
- 接着进入编码器的核心部分,把输入表示成一种更抽象的表示形式,这个表示形式也是向量,即一串数字。里面既保留了输入文本的词汇信息和顺序关系,也捕捉了语法语义上的关键特征。捕捉关键特征的核心是编码器的自注意力机制。模型在处理每个词的时候,不仅会关注这个词本身和它附件的词,还会关注输入序列中的其他所有词。同时Transformer使用多头注意力机制,也就是编码器不只有一个自注意力模块,而是有多个,每个头有不同的自注意力权重,用来关注文本里不同特征或方面。比如有的关注动词,有的关注修饰词,有的关注情感,有的关注命名实体等等,而且可以做并行运算,也就是计算进展上互不影响。
- 多头自注意力后面,还有一个前馈神经网络。他会对自注意力模块的输出进行进一步的处理,增强模型的表达能力
- 编码器在Transformer里不止有一个,实际上是有多个堆叠在一起。每个编码器内部结构一样,但不共享权重,这让模型能更深入的理解数据处理更复杂的文本语言内容
token可以理解为是文本的一个基本单位。短的英文单词,可能一个词是一个token,而长的词可能被分为多个token。而中文的话,所占的token数量会相对更多,有些字要用一个甚至更多token表示
嵌入层的作用:把每个token都用向量表示。向量,即一串数字,他能表达的含义远远大于一个数字,能包含更多语法语义信息。词向量不仅可以帮模型理解词的语义,也可以捕捉词与词之间的复杂关系(提出Transformer的文章里,向量长度是512,GPT-3是12288)
位置编码:把表示各个词在文本里顺序的向量和上一步得到的词向量相加
自注意力机制,通过计算每对词之间的相关性来决定注意力权重。两个词之间的相关性越强,它们之间的注意力权重就会越高。自注意力机制涉及很多计算步骤,更多细节请参考论文原文Attention Is All You Need
- 假如我们想要将一个英文橘子转化为法语,比如输入:
解码器部分:
- 他是大语言模型生成一个个词的关键。
- 通过前面的编码器。我们有了输入序列里各个token的抽象表示,可以把它传给解码器。解码器还会先接收一个特殊值,这个值表示输出序列的开头。这样做的原因是,解码器不仅会把来自编码器的输入序列的抽象表示作为输入,还会把之前已经生成的文本也作为输入,来保持输出的连贯性和上下文相关性。刚开始生成的这轮,还没有任何已生成的文本,所以把表示开头的特殊值先作为输入,具体的生成过程仍然是要经过多个步骤
- 首先跟编码器一样,文本要经过我们已经了解过的嵌入层和位置编码,然后被输入进多头自注意力层。但他和编码器里的自注意力层有点不一样,当编码器在处理各个词的时候,它会关注输入序列里所有其他词,但解码器中,自注意力只会关注这个词和它前面的其他词,后面的词要被遮住,不去关注。这样做是为了确认解码器在生成文本时遵循正确的时间顺序,不能给他偷看到后面。在预测下一个词时,只使用前面的词作为上下文。这种类型的多头自注意力,被叫做带掩码的多头自注意力。带掩码的多头自注意力,是针对已生成的输出序列的
- 而后面解码器还有个多头自注意力层,这里就是前面编码器所输出的,输入序列的抽象表示所派上用场的地方。注意力会捕捉编码器的输出和解码器即将生成的输出之间的对应关系,从而将原始输入序列的信息融合到输出序列的生成过程中。
- 解码器里的前馈神经网络和编码器里的类似,也是通过额外的计算来增强模型的表达能力。
- 和编码器一样,解码器同样是多个堆叠到一起的,这可以增强模型的性能,有助于处理复杂的输入输出关系
- 解码器的最后阶段,包含一个线性层和一个Softmax层,它们俩加一块的作用是,把解码器输出的表示转化为词汇表的概率分布
- 词汇表的概率分布,代表下一个被生成token的概率,有些token的概率比其他值高,在大多数情况下模型会选择概率最高的token作为下一个输出
- 解码器本质上在猜下一个最可能的输出,至于输出是否符合客观事实,模型无从得知,所以我们也能看到模型一本正经的胡说八道,这种现象叫做幻觉
- 解码器的一整个流程会重复多次,新的token会持续生成,直到生成的是一个用来表示输出序列结束的特殊token
小结:
- 编码器用来理解和表示输入序列,解码器用来生成输出序列
- 实际上,在原始架构的基础上,后续出现了一些变种,主要有三个类别:仅编码器,仅解码器,以及编码器-解码器
- 仅编码器模型,也叫自编码器模型,只保留了原始架构里的编码器,如BERT。此类模型适用于理解语言的任务,比如掩码语言建模,也就是让模型猜文本里被遮住的词是什么;情感分析,让模型判断文本情感是积极还是消极,等等
- 仅解码器模型,也叫自回归型模型,只保留了原始架构里的解码器,GPT系列都是这种模型的例子,这类模型非常擅长通过预测下一个词来实现文本生成,我们已经在ChatGPT上见识过了
- 编码器-解码器模型,也叫序列到序列模型,同时保留了原始架构里的编码器和解码器,例如T5,BART。此类模型适用于把一个系列转换成另一个序列的任务,比如翻译、总结等等
4. 炼成ChatGPT
炼成ChatGPT拢共分三步:
- 无监督学习:通过大量文本进行无监督学习预训练,得到一个能进行文本生成的基座模型
- 首先需要海量文本作为原料,让模型从中学习。比如GPT-3这个基座模型的训练数据,有多个互联网文本语料库,覆盖书籍、新闻文章、科学论文、维基百科等等,训练数据的整体规模是3000亿token
- 有了大量可用于训练的文本后,要采用无监督学习的方式训练模型
- 预训练不是一个容易的过程,是这四个步骤里最耗时、费钱的。
- 预训练得到一个基座模型。基座模型不等同于ChatGPT背后的对话模型,因为此时模型有预测下一个token的能力,会根据上文补充文本,但并不擅长对话。比如你问他一个问题,他可能模仿你的问题生成更多的问题。为了解决这个问题,我们需要进行第二步,对基座模型进行微调
- 监督微调:通过一些人类撰写的高质量对话数据,对基座模型进行监督微调,得到一个微调后的基座模型。此时的模型除了具备续写文本之外。也会获得更好的对话能力
- 微调就是在已有模型上做进一步的训练,会改变模型的内部参数,让模型更加适应特定任务。换句话说,为了训练更适合对话的ai助手,需要给基座模型看更多的对话数据
- 微调的成本相比于预训练的成本低很多,因为需要的训练数据的规模更小,训练时长更短。在这一阶段里,模型不需要从海量文本中学习,而是从一些人类写的专业且高质量的回答里学习。这相当于给了模型问题,也给了模型我们中意的回答,属于监督学习,所以这一过程被叫做监督微调(Supercised Fine-Tuning, SFT)
- 完成后会得到一个SFT模型,他相比较步骤一得到的模型,更加擅长对问题做出回答。但为了对模型的实力继续提升,还能进行第三步,让SFT模型进行强化学习
- 训练奖励模型+强化学习训练:用问题和多个对应回答的数据,让人类标注员对回答进行质量排序,然后基于这些数据,训练出一个能对回答进行评分预测的奖励模型。接下来,让第二步得到的模型对问题生成回答,用奖励模型给回答进行评分,利用评分进行反馈,进行强化学习训练
- 对SFT模型进行强化学习。我们可以让ChatGPT对问题做出回答,然后让人类评估员去给回答打分
- 打分主要基于3H原则:Helpful(有用性), Honest(真实性), Harmless(无害性)。如果打分高的话模型知道要再接再厉,打分低的话模型就学习到要予以改进。但是,让人类给模型一个个打分,成本极高,效率极低。所以要训练出一个模型,让模型给模型打分。所以在这一个步骤里,需要训练一个奖励模型
- 奖励模型,是从回答以及回答对应的评分里学习的。得到评分数据的方式是,让微调后的GPT模型,也就是第二步里得到的SFT模型,对每个问题生成多个回答,然后让人类标注员对回答质量进行比较排序。虽然还是免不了人类标注员的劳动,但一旦有了足够的排序数据,就可以把数据用在训练奖励模型上,让奖励模型学习预测回答的评分
- 奖励模型训练出来后,就可以用在强化学习上了。强化学习里,ChatGPT模型的最初参数来自之前得到的SFT模型但会随着训练而更新。奖励模型的参数则不会被更新,它的任务就是对模型生成的内容打分
- 经过一轮又一轮的迭代之后,模型会不断优化策略,回答的质量会进一步提升,强大的ChatGPT就炼成了
5. 调教ChatGPT
提示工程(Prompt Engineering):研究如何提高和AI的沟通质量及效率,核心关注提示的开发和优化
- 提示就是我们给AI聊天助手输入的问题或指令,AI会根据提示内容给予回应
ChatGPT等聊天助手存在的局限性:他们背后的大语言模型是用海量文本训练出来的,因此擅长模仿人类语言表达,也从那些内容里学到了不少知识,他们的回应都是根据提示以及前面已生成的内容,通过持续预测下一个token的概率来实现的。但同时,对于他们不了解的领域,他们并不知道自己缺乏那方面的知识,加上生成过程中并没有反思能力,所以会经常看到胡说八道的同时还充满着自信。
如何调教AI给出想要的回答?
- 小样本提示:我们很多时候都是直接丢问题或指令给ai,这属于零样本提示,就是没有给AI示范,不一定和我们想要的效果相符合。但如果我们在ai回答前,给他几个对话作为示例,用样本对他进行引导,AI模型就会利用上下文学习能力,一方面作为记忆那些内容作为知识,另一方面,像示范那样模仿着进行回应。有了小样本提示后,再给出AI类似的问题,他就能给出和提示示范相似的回答了
- 思维链:AI不擅长做数学题,因为它不会因为某个词需要涉及更多的思考,而花费更多时间生成那个token,即使前面有正确的示范答案也没什么帮助。这种时候可以借助思维链。思维链的使用方法是,我们给AI的小样本提示里,不仅包含正确的结果,也展示中间的推理步骤,AI在生成回答时,也会模仿着去生成一些中间步骤,把过程进行分解。
- 在思维链的相关论文里,作者还提到,即使我们不用小样本提示,只是在问题后面加一句:Let's think step by step.让我们来分步骤思考,也能提升AI得到正确答案的概率
6. 武装ChatGPT
ChatGPT的短板:编造事实、计算不准确、数据过时等等。为了应对这些问题,可以借组一些外部工具或数据,把AI武装起来。实现这一思路的框架包括
RAG、PAL、ReAct- RAG(Retrieval Augmented Generation, 检索增强生成):
- 对于一些小众领域,我们无法指望ChatGPT帮我们回答相关问题。一个应对方法是,我们可以提供外部文档,让模型访问外部知识库,获得实时且正确的数据,生成更可靠和准确的回答,这种架构就是检索增强生成。
- 具体来说,外部知识文档要先被切分成一个个段落,因为大语言模型一次性能接收的文本长度有限,然后每个段落会被转成一系列向量。向量可以被看作是一串固定长度的数字,然后储存进向量数据库里。当我们提出问题的时候,这个提示也会被转换为向量,然后查找向量数据库里,和用户的查询向量最为接近的段落向量。找到以后,段落信息回合原本的用户查询问题组合到一起,一块传给AI。这样,AI就能把外部文档的段落作为上下文,基于里面的信息给出更严谨的回答。因此,你可以对外部文档里任何内容进行提问,即使AI模型没有受到过那些内容的训练
- RAG有利于搭建企业知识库和个人知识库,CHatGPT的一些插件就是基于RAG架构的,官方也推出了上传PDF之后,对PDF进行提问的功能。如果你会使用ChatGPT的API,还可以用代码实现自己的索引增强生成
- PAL(Program-Aided Language Models,
程序辅助语言模型):
- 大语言模型还有一个问题,我们没法把它当作计算器,当我们问他一个数学计算后,他没有真正帮忙做计算,只是在猜下一个最可能的token来生成回答。但如果我们不让他做计算,而是把计算后的结果告诉他呢?PAL可以帮助我们解决此类问题。
- PAL的核心在于,我们不让AI直接生成计算结果,而是借助其他善于做计算的工具,比如Python解释器。那我们对AI的需求,就变成了生成得到计算结果所需的代码。具体来说,首先,为了让AI遵循我们的需求,可以借助思维链。我们现在小样本提示里,通过样本示例,给模型示范如何分步骤思考,写出解决问题所需的变量赋值、数学运算等代码,让模型照猫画虎。在用户提问后,把用户的问题和我们已有的提示模板进行拼接,一并给到AI,让AI生成代码。接下来,把AI返回的回答给到Python解释器,让Python解释器执行并返回计算的结果,这个回答再给回到AI,让AI带着计算答案对用户的回答进行妥善回复
- 现在我们用了大语言模型接收问题的耳朵、思考的脑子、说话的嘴,以及代码解释器做运算的手
- ReAct(Reason Action, 推理行动结合):
- ChatGPT所了解的知识,天然受到训练数据日期的影响。比如说,模型是去年训练完成的,训练数据里必然不包含今年的新闻,模型也无从得知训练完成后发生的事情,这被称为知识截断。当我们问模型最近发生的事实时,模型要么回复已过时的信息,要么会胡编乱造一通。但重新训练模型的成本是相当高的,也无法彻底解决数据过时的问题
- ReAct的核心在于,让模型进行动态推理,并采取行动与外界环境互动。它同样能与思维链结合。我们会用小样本示例,展示给模型一个推理与行动结合的框架,也就是针对问题,把步骤进行拆分。每个步骤要经过推理、行动、观察,推理是针对问题或上一步观察的思考,行动是基于推理,与外部环境的一些交互,比如用搜索引擎对关键词进行一些搜索,观察是对行动得到的结果进行查看
- 神经网络可以用于
{kind=link}